
Lenguajes. Conceptos fundamentales
Sea Σ una colección finita de símbolos. Este conjunto de símbolos se denomina alfabeto y los elementos letras. Una palabra sobre Σ es una cadena de longitud finita de elementos de Σ. La cadena vacía o cadena nula, denotada por ε, es una cadena que no contiene símbolos. El conjunto de todas las palabras sobre Σ se denota Σ ∗ . ε es una palabra en cualquier alfabeto Σ. Un lenguaje sobre Σ es un subconjunto de Σ ∗ .
Si L denota el conjunto de los lenguajes sobre Σ se tiene que L = {L : L ⊂ Σ ∗} Note que ε, la cadena vacía, es la cadena que no contiene símbolos. Es diferente de ∅ el conjunto vacío (lenguaje vacío). Se sigue que {ε} es el conjunto que contiene exactamente una cadena, de hecho, la cadena vacía. La longitud de una palabra u ∈ Σ ∗ , denotada por |u|, es el número de posiciones que tiene la palabra. Se puede definir recursivamente de esta manera:
|ε| = 0 |ua| = |u| + 1
donde
u ∈ Σ ∗ y a ∈ Σ.
De este modo una palabra u ∈ Σ ∗ se puede definir por una función u : {1, 2, . . . , |u|} → Σ donde u(i) es la letra que se encuentra en la posición i en la palabra u. Dos palabras u, v ∈ Σ ∗ son iguales si
|u| = |v| y u(i) = v(i) para 1 ≤ i ≤ |u|.
Definimos una operación sobre Σ ∗ denominada concatenación. Para u, v ∈ Σ ∗ la concatenación de u y v se denota uv y se define a través de la función uv : {1, 2, . . . , |u| + |v|} → Σ uv(i) = ½ u(i), si 1 ≤ i ≤ |u| v(i − |u|), si |u| + 1 ≤ i ≤ |u| + |v| Así la palabra uv es la palabra que se obtiene escribiendo las letras de u y luego las letras de v. Si u = u1u2 · · · uk y v = v1v2 · · · vs entonces uv = u1u2 · · · ukv1v2 · · · vs donde ui , vj ∈ Σ. Se deja al lector verificar que esta operación es asociativa.
Ejercicio 1 Pruebe que |uv| = |u| + |v|
Definición 1 Dados dos lenguajes L, M ∈ L, la concatenación de los lenguajes L y M se denota por LM y se define LM = {vw : v ∈ L, w ∈ M}
Es fácil ver que la concatenación de lenguajes es asociativa.
Ejemplo 1 Sean Σ = {0, 1} y L, M dos lenguajes sobre Σ dados por L = {1, 10} y M = {1, 01} entonces LM = {11, 101, 1001}. Mientras que ML = {11, 110, 001, 0110}. Definición 2 Si Σ es un alfabeto y n ∈ N se define las potencias de Σ recursivamente de la siguiente manera: 1) Σ1 = Σ 2) Σn+1 = ΣΣn Por convención se tiene que Σ 0 = {ε}.
Ejemplo 2 Si Σ = {a, b, c} entonces Σ 2 = {aa, ab, ac, ba, bb, bc, ca, cb, cc}
Ejercicio 2 Pruebe que Σ ∗ = S n≥0 Σ n. Definimos Σ + = S n≥1 Σ n. Este es el conjunto de todas las palabras de longitud mayor que 1. Puesto que ε nunca es elemento de nuestro alfabeto, es decir, ε /∈ Σ entonces Σ ∗ 6= Σ+ y Σ ∗ = Σ+ ∪ {ε} Definición 3 Para L un lenguaje se define de manera recursiva L n así: L 0 = {ε} L n+1 = LLn L ∗ se define L ∗ = [ n≥0 L n L ∗ se denomina la Cerradura de Kleene o Cerradura estrella de L.
Ejemplo 3 Sea Σ = {0, 1} y L = {01, 1},
entonces L 3 = {010101, 01011, 01101, 0111, 10101, 1011, 1101, 111}
Lenguajes y Expresiones Regulares
En aritmética, usamos las operaciones + y × para construir expresiones tales como (4 + 1) × 5 De manera similar, usamos operaciones regulares para construir expresiones que describen lenguajes, las cuales se denominan expresiones regulares. Un ejemplo es: (0 ∪ 1)0∗ El valor de la expresión aritmética es 25. El valor de una expresión regular es un lenguaje. En este caso el lenguaje consiste en todas las palabras que empiezan con 1 o 0 seguido por cualquier número (finito) de 0 s. Otro ejemplo de una expresión regular es (0 ∪ 1)∗ Empieza con el lenguaje (0 ∪ 1) y se aplica la operación * . El valor de esta expresión son todas las palabras posibles de 0 s y 1s.
Lenguajes Regulares
Para un alfabeto Σ dado, los lenguajes regulares constituyen el menor conjunto de lenguajes sobre Σ que es cerrado respecto a las operaciones de concatenación, la cerradura de Kleene y la unión de lenguajes y además contiene el lenguaje ∅ y los lenguajes unitarios {a} para a ∈ Σ. Definición 4 Sea Σ un alfabeto. El conjunto de lenguajes regulares sobre Σ se define recursivamente como sigue:
1. ∅ y {ε} son lenguajes regulares
2. Para toda a ∈ Σ, {a} es un lenguaje regular.
3. Si L y M son lenguajes regulares, entonces L ∪ M, LM, L∗ son lenguajes regulares. 4. Ningún otro lenguaje sobre Σ es regular.
Ejemplo 4 Dado Σ = {a, b}, las siguientes afirmaciones son verdaderas: ∅ y {ε} son lenguajes regulares. {a} y {b} son lenguajes regulares. {a, b} es un lenguaje regular. {ab} es regular. {a i |i ≥ 0} es regular.
La jerarquía de Chomsky
Llamamos “clase de lenguajes” a conjuntos de lenguajes que comparten una cierta propiedad dada. Esta noción es muy abstracta, pues ya los lenguajes son en sí mismos conjuntos de secuencias de símbolos, y las clases de lenguajes son entonces conjuntos de conjuntos de secuencias de símbolos. La clasificación de lenguajes en clases de lenguajes es debida a N. Chomsky [4], quien propuso una jerarquía de lenguajes, donde las clases más complejas incluyen a las más simples. De las clases de lenguajes propuestas en la jerarquía de Chomsky, nosotros estudiaremos las que aparecen en la figura 1.3, que son:
Los “Lenguajes Regulares”, que es la clase más pequeña, e incluye a los lenguajes m{as simples. 10 Un ejemplo de lenguaje regular es el conjunto de todos los número binarios. Los “Lenguajes Libres de Contexto”, que incluyen a los Lenguajes Regulares. Por ejemplo, la mayoría de los lenguajes de programación son Lenguajes Libres de Contexto. Los “Lenguajes Recursivamente Enumerables”, que incluyen a los Libres de Contexto (y por lo tanto a los Lenguajes Regulares).
Todas estas clases de lenguajes son representables de manera finita (mediante cadenas de caracteres que sirven como representación). Ahora bien, como veremos más adelante, hay más lenguajes que posibles representaciones finitas, por lo que podemos saber que hay lenguajes más allá de los Recursivamente Enumerables. Sin embargo, desde un punto de vista práctico, los lenguajes más útiles son aquellos que tienen una representación finita, por lo que los demás lenguajes son sólo de interés teórico. En capítulos posteriores veremos que cada una de estas clases de lenguajes está asociada a un tipo de “autómata” capaz de procesar estos lenguajes. Esto ha hecho pensar que las categorías de lenguajes de Chomsky no son completamente arbitrarias.
Autómatas finitos
El término máquina evoca algo hecho en metal, usualmente ruidoso y grasoso, que ejecuta tareas repetitivas que requieren de mucha fuerza o velocidad o precisión. Ejemplos de estas máquinas son las embotelladoras automáticas de refrescos. Su diseño requiere de conocimientos en mecánica, resistencia de materiales, y hasta dinámica de fluidos. Al diseñar tal máquina, el plano en que se le dibuja hace abstracción de algunos detalles presentes en la máquina real, tales como el color con que se pinta, o las imperfecciones en la soldadura.
El plano de diseño mecánico de una máquina es una abstracción de ´esta, que es útil para representar su forma física. Sin embargo, hay otro enfoque con que se puede modelar la máquina embotelladora: cómo funciona, en el sentido de saber qué secuencia de operaciones ejecuta. As´ı, la parte que introduce el líquido pasa por un ciclo repetitivo en que primero introduce un tubo en la botella, luego descarga el líquido, y finalmente sale el tubo para permitir la colocación de la cápsula (“corcholata ”).
El orden en que se efectúa este ciclo es crucial, pues si se descarga el líquido antes de haber introducido el tubo en la botella, el resultado no ser´a satisfactorio. El modelado de una máquina en lo relacionado con secuencias o ciclos de acciones se aproxima más al enfoque que adoptaremos en este curso. Las máquinas que estudiaremos son abstracciones matemáticas que capturan solamente el aspecto referente a las secuencias de eventos que ocurren, sin tomar en cuenta ni la forma de la máquina ni sus dimensiones, ni tampoco si efectúa movimientos rectos o curvos, etc.
Estados finales


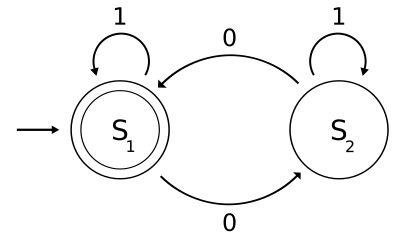
El propósito de algunos modelos de estados y eventos es el de reconocer secuencias de eventos “buenas”, de manera que se les pueda diferencias de las secuencias “malas”. Supóngase, por ejemplo, que se quiere modelar el funcionamiento de una máquina automática vendedora de bebidas enlatadas. Dicha máquina acepta monedas de valor 1, 2 y 5, y el precio de cada lata es de 5.
Vamos a considerar que el evento llamado “1” es la introducción de una moneda de valor 1 en la máquina, el evento “2” para la moneda de valor 2, etc. La primera cuestión que hay que resolver para diseñar nuestro modelo es decidir cómo son los estados. Una buena idea sería que cada estado recordara lo que se lleva acumulado hasta el momento.
El estado inicial, desde luego, recordaría que se lleva acumulado 0. Con estas ideas podemos hacer un diagrama de estados y eventos como el de la figura 2.3. Muchas transiciones en dicho diagrama son evidentes, como el paso del estado “1” al “3” tras la introducción de una moneda de valor 2. En otros casos hay que tomar una decisión de diseño conflictiva, como en el caso en que en el estado “4” se introduzca una moneda de valor 2. En el diagrama presentado, se decidió que en ese caso se va al estado “5”, lo que en la práctica
Máquinas de Estados Finitos

A partir de ahora vamos a considerar modelos de estados y eventos un poco más abstractos que los que hemos visto antes. Retomemos el ejemplo de la máquina vendedora de latas, que vimos en la sección 2.1.1. En ese modelo pudimos reconocer secuencias de eventos “aceptables”, como la secuencia de monedas 2, 2, 1 con respecto a secuencias no aceptables, como 1, 1, 1. A partir de ahora los nombres de los eventos van a estar formados por un carácter, y les llamaremos transiciones en vez de “eventos”. De este modo, en vez de un evento “meter 1” vamos a tener una transición con el carácter “1”, por ejemplo. Desde luego, la elección de qué carácter tomar como nombre de la transición es una decisión arbitraria. Además, las secuencias de eventos van a representarse por concatenaciones de caracteres, esto es, por palabras. As´ı, en el ejemplo de la máquina vendedora la palabra “1121” representa la secuencia de eventos “meter 1”, “meter 1”, “meter 2”, “meter 1”.
Desde el punto de vista abstracto que vamos a adoptar a partir de ahora, nuestras máquinas pueden ser visualizadas como dispositivos con los siguientes componentes: (ver figura 2.5) Una cinta de entrada; Una cabeza de lectura (y eventualmente escritura); Un control. La cabeza lectora se coloca en los segmentos de cinta que contienen los caracteres que componen la palabra de entrada, y al colocarse sobre un carácter lo “lee” y manda esta información al control; también puede recorrerse un lugar a la derecha (o a la izquierda también, seg´un el tipo de máquina). El control (indicado por una caratula de reloj en la figura) le indica a la cabeza lectora cu´ando debe recorrerse a la derecha. Se supone que hay manera de saber cuando se acaba la entrada (por ejemplo, al llegar al blanco). La “aguja” del control puede estar cambiando de posición, y hay algunas posiciones llamadas finales (como la indicada por un punto, q3) que son consideradas especiales, por que permiten determinar si una palabra es aceptada o rechazada, como veremos más adelante.
Métodos de diseño de AFDs
Considérese el problema de construir un AFD que acepte exactamente un lenguaje dado. Este problema es comúnmente llamado “problema de diseño”. No es conveniente proceder por “ensayo y error”, puesto que en general hay que considerar demasiadas posibilidades, y es muy fácil equivocarse. Más a´un, hay dos maneras de equivocarse al diseñar un AFD.
1. Que “sobren palabras”, esto es, que el autómata acepte algunas palabras que no debería aceptar. En este caso decimos que la solución es incorrecta.
2. Que “falten palabras”, esto es, que haya palabras en el lenguaje considerado que no son aceptadas por el AFD, cuando deberían serlo. En este caso decimos que la solución es incompleta.
Por ejemplo, supongamos que alguien propone el autómata para el lenguaje de las palabras en el alfabeto {a, b} que no tienen varias a’s seguidas. Esta solución es defectuosa, porque:
1. Hay palabras, como “baa”, que tiene a’s seguidas y sin embargo son aceptadas por el AFD.
2. Hay palabras, como “ba”, que no tienen a’s seguidas y sin embargo no son aceptadas por el AFD.
Máquinas de Moore
En las maquinas de Moore la salida depende del estado en que se encuentra el autómata. Dicha salida es producida una vez, y cuando se llega a otro estado (o al mismo) por efecto de una transición, se produce el símbolo de salida asociado al estado al que se llega. Algunos estudiantes encuentran ´util la analog´ıa de los autómatas de Moore con nociones de electricidad: es como si cada estado tuviera un “nivel de voltaje” que se produce en la salida mientras el control se encuentre en dicho estado. Las máquinas de Moore se representan gráficamente como cualquier AFD, al que se a˜nade, al lado de cada estado, la salida asociada, que es una cadena de caracteres. Por ejemplo, consideremos un autómata que invierte la entrada binaria recibida (esto es, cambia un 1 por 0 y un 0 por 1). Dicho autómata se representa gráficamente en la figura 2.19(a).
Para formalizar los autómatas de Moore una idea sencilla es a˜nadir a un AFD estándar una función que asocie a cada estado una palabra de salida; llamaremos λ a esta función. También vamos a agregar un alfabeto de salida Γ, que puede ser distinto al de entrada. Todos los demás aspectos permanecen igual que en un AFD. Definición.- Una máquina de Moore es un séxtuplo (K, Σ, Γ, δ, λ, q0), en donde K, Σ y δ son como en los AFD, y q0 es el estado inicial; además tenemos a Γ que es el alfabeto de salida, y λ, que es una función de K a Γ∗ , que obtiene la salida asociada a cada estado; la salida es una cadena de caracteres tomados de Γ
Máquinas de Mealy
En las máquinas de Mealy la salida producida depende de la transición que se ejecuta, y no solamente del estado. Por esto, en la notación gráfica las etiquetas de las flechas son de la forma σ/w, donde σ es el carácter que se consume de entrada, y w es la palabra que se produce en la salida. Por ejemplo, el diagrama para el inversor binario, implementado como máquina de Mealy.
Para formalizar las máquinas de Mealy, una idea podría ser aumentarle a las transiciones la palabra producida en la salida. Sin embargo, por modularidad se prefiere definir una función de salida λ, pero que, a diferencia de las máquinas de Moore, ahora toma como entrada un estado y un carácter de entrada. En efecto, podemos darnos cuenta de que es lo mismo que la salida dependa del estado y un carácter, a que dependa de una transición.
Definición.- Una máquina de Mealy es un séxtuplo (K, Σ, Γ, δ, λ, q0), en el que todos los componentes tienen el mismo significado que arriba, a excepción de λ, que es una función λ : K × Σ → Γ ∗ , esto es, toma un elemento de K × Σ –que incluye un estado y un carácter de entrada– y produce una palabra formada por caracteres de Γ.
K = {q0}, Σ = {0, 1}, δ(q0) = q0, y λ(q0, 1) = 0, λ(q0, 0) = 1. La salida de una m´aquina de Mealy ante una entrada a1 . . . an es λ(q0, a1) λ(q1, a2) . . . λ(qn−1, an), donde qi = δ(qi−1, ai), para 1 ≤ i ≤ n.
Equivalencia de las máquinas de Moore y Mealy
Aunque muchas veces, para un mismo problema, la máquina de Mealy es más simple que la correspondiente de Moore, ambas clases de máquinas son equivalentes. Si despreciamos la salida de las m´aquinas de Moore antes de recibir el primer carácter (o sea, con entrada ε), es posible encontrar, para una m´aquina de Moore dada, su equivalente de Mealy, en el sentido de que producen la misma salida, y viceversa. La transformación de una máquina de Moore en máquina de Mealy es trivial, pues hacemos λMealy(q, a) = λMoore(δMoore(q, a)), es decir, simplemente obtenemos qué salida producir´a una transición de Mealy viendo la salida del estado al que lleva dicha transición en Moore. Por ejemplo, la máquina de Mealy de la figura 2.19(b) se puede transformar de esta manera a la máquina de Moore que aparece en la figura 2.19(c). La transformación de una máquina de Mealy en Moore es más complicada, pues en general hay que crear estados adicionales; remitimos al alumno a la referencia.
Autómatas finitos no deterministas
Una extensión a los autómatas finitos deterministas es la de permitir que de cada nodo del diagrama de estados salga un n´umero de flechas mayor o menor que |Σ|. As´ı, se puede permitir que falte la flecha correspondiente a alguno de los símbolos del alfabeto, o bien que haya varias flechas que salgan de un sólo nodo con la misma etiqueta. Inclusive se permite que las transiciones tengan como etiqueta palabras de varias letras o hasta la palabra vacía. A estos autómatas finitos se les llama no determinísticos o no deterministas (abreviado AFN), por razones que luego veremos. Al retirar algunas de las restricciones que tienen los autómatas finitos determinísticos, su diseño para un lenguaje dado puede volverse más simple. Por ejemplo, un AFN que acepte. las palabras en {a, b} que contienen la subcadena abbab se ilustra en la figura 2.23. Hacemos notar en este punto que, dado que los AFN tienen menos restricciones que los AFD, resulta que los AFD son un caso particular de los AFN, por lo que todo AFD es de hecho un AFN.
Expresiones Regulares y Gramáticas Regulares
En este capítulo estudiaremos la clase de lenguajes aceptados por los AF, la de los lenguajes regulares, que es al mismo tiempo una de las de mayor utilidad práctica. Como se aprecia en la figura 1.3, los Lenguajes Regulares son los más simples y restringidos dentro de la jerarquía de Chomsky que presentamos anteriormente. Estos lenguajes pueden además ser descritos mediante dos representaciones que veremos: las Expresiones Regulares y las Gramáticas Regulares.
Lenguajes Regulares
Los lenguajes regulares se llaman as´ı porque sus palabras contienen “regularidades” o repeticiones de los mismos componentes, como por ejemplo en el lenguaje L1 siguiente:
L1 = {ab, abab, ababab, abababab, . . .}
En este ejemplo se aprecia que las palabras de L1 son simplemente repeticiones de “ab” cualquier n´umero de veces. Aqu´ı la “regularidad” consiste en que las palabras contienen “ab” alg´un n´umero de veces. Otro ejemplo m´as complicado ser´ıa el lenguaje
L2: L2 = {abc, cc, abab, abccc, ababc, . . .}
La regularidad en L2 consiste en que sus palabras comienzan con repeticiones de “ab”, seguidas de repeticiones de “c”. Similarmente es posible definir muchos otros lenguajes basados en la idea de repetir esquemas simples. Esta es la idea básica para formar los lenguajes Regulares. Adicionalmente a las repeticiones de esquemas simples, vamos a considerar que los lenguajes finitos son también regulares por definición. Por ejemplo, el lenguaje L3 = {anita, lava, la, tina} es regular. Finalmente, al combinar lenguajes regulares uniéndolos o concatenándolos, también se obtiene un lenguaje regular.
Por ejemplo, L1 ∪ L3 = {anita, lava, la, tina, ab, abab, ababab, abababab, . . .} es regular. También es regular una concatenación como L3L3 = {anitaanita, anitalava, anitala, anitatina, lavaanita, lavalava, lavala, lavatina, . . .}
Gramáticas regulares
En esta sección veremos otra manera de representar los lenguajes regulares, además de las Expresiones Regulares que ya vimos.
Gramáticas formales.
La representación de los lenguajes regulares que aquí estudiaremos se fundamenta en la noción de gramática formal. Intuitivamente, una gramática es un conjunto de reglas para formar correctamente las frases de un lenguaje; as´ı tenemos la gramática del español, del francés, etc. La formalización que presentaremos de la noción de gramática es debida a N. Chomsky [4], y está basada en las llamadas reglas gramaticales. Una regla es una expresión de la forma α → β, en donde tanto α como β son cadenas de símbolos en donde pueden aparecer tanto elementos del alfabeto Σ como unos nuevos símbolos, llamados variables. Los símbolos que no son variables son constantes. 8 Por ejemplo, una posible regla gramatical es X → aX. La aplicación de una regla α → β a una palabra uαv produce la palabra uβv. En consecuencia, las reglas de una gramática pueden ser vistas como reglas de reemplazo. Por ejemplo, si tenemos una cadena de símbolos bbXa, le podemos aplicar la regla X → aX, dando como resultado la nueva cadena bbaXa.
Gramáticas regulares
Nosotros nos vamos a interesar por el momento en las gramáticas cuyas reglas son de la forma A → aB o bien A → a, donde A y B son variables, y a es un carácter terminal. A estas gramáticas se les llama regulares.
Ejemplo.- Sea una gramática con las siguientes reglas:
1. S → aA
2. S → bA
3. A → aB
4. A → bB
5. A → a
6. B → aA
7. B → bA
La idea para aplicar una gramática es que se parte de una variable, llamada símbolo inicial, y se aplican repetidamente las reglas gramaticales, hasta que ya no haya variables en la palabra. En ese momento se dice que la palabra resultante es generada por la gramática, o en forma equivalente, que la palabra resultante es parte del lenguaje de esa gramática.
Autómatas finitos y gramáticas regulares De manera similar a como hicimos en la sección anterior, aquí vamos a establecer la equivalencia entre las gramáticas regulares y los lenguajes regulares -y por ende los autómatas finitos. Este resultado es establecido por el siguiente Teorema.- La clase de los lenguajes generados por alguna gramática regular es exactamente la de los lenguajes regulares. La prueba de este teorema consiste en proponer un procedimiento para, a partir de una gramática dada, construir un autómata finito, y viceversa. Dicho procedimiento es directo, y consiste en asociar a los símbolos no terminales de la gramática (las variables) los estados de un autómata. As´ı, para cada regla A → bC en la gramática tenemos una transición (A, b, C) en el autómata. Sin embargo, queda pendiente el caso de las reglas A → b. Para estos casos, se tienen transiciones (A, b, Z), donde Z es un nuevo estado para el que no hay un no terminal asociado; Z es el único estado final del autómata.
Ejemplo.- Obtener un autómata finito para la gramática regular G siguiente:
1. S → aA
2. S → bA
3. A → aB
4. A → bB
5. A → a
6. B → aA
7. B → bA
Gram´aticas y lenguajes libres de contexto
Los Lenguajes Libres de Contexto (abreviado LLC) forman una clase de lenguajes más amplia que los Lenguajes Regulares, de acuerdo con la Jerarquía de Chomsky (ver sección 1.5). Estos lenguajes son importantes tanto desde el punto de vista teórico, por relacionar las llamadas Gramáticas Libres de Contexto con los Autómatas de Pila, como desde el punto de vista práctico, ya que casi todos los lenguajes de programación están basados en los LLC. En efecto, a partir de los a˜nos 70’s, con lenguajes como Pascal, se hizo común la práctica de formalizar la sintaxis de los lenguajes de programación usando herramientas basadas en las Gramáticas Libres de Contexto, que representan a los LLC. Por otra parte, el análisis automático de los LLC es computacionalmente mucho más eficiente que el de otras clases de lenguajes más generales. Retomaremos aquí las nociones relacionadas con las gramáticas, que fueron introducidas en la sección 3.5, pero haciendo las adaptaciones necesarias para los LLC. Una regla es una expresión de la forma α → β, en donde tanto α como β son cadenas de símbolos en donde pueden aparecer tanto elementos del alfabeto Σ (llamados constantes) como unos nuevos símbolos, llamados variables.
Gramáticas y la jerarquía de Chomsky
Es posible restringir la forma de las reglas gramaticales de manera que se acomoden a patrones predeterminados. Por ejemplo, se puede imponer que el lado izquierdo de las reglas sea una variable, en vez de una cadena arbitraria de símbolos. Al restringir las reglas de la gramática se restringen también las palabras que se pueden generar; no es extraño que las reglas de formas mas restringidas generan los lenguajes más reducidos. N. Chomsky propuso [4] varias formas estándares de reglas que se asocian a varias clases de lenguajes, que orden´o de manera tal que forman una jerarquía, es decir, los lenguajes más primitivos están incluidos en los m´as complejos. Así tenemos las siguientes clases de gramáticas, asociadas a familias de lenguajes:
1. Gramáticas regulares, o de tipo 3: las reglas son de la forma A → aB o bien A → a, donde A y B son variables y a es constante. 6 Estas gramáticas son capaces de describir los lenguajes regulares.
2. Gramáticas Libres de Contexto (GLC), o de tipo 2: las reglas son de la forma X → α, donde X es una variable y α es una cadena que puede contener variables y constantes. Estas gramáticas producen los lenguajes Libres de Contexto (abreviado “LLC”).
3. Gramáticas sensitivas al contexto o de tipo 1: las reglas son de la forma αAβ → αΓβ, donde A es una variable y α,β y Γ son cadenas cualesquiera que pueden contener variables y constantes.
4. Gramáticas no restringidas, o de tipo 0, con reglas de la forma α → β, donde α no puede ser vacío, que generan los lenguajes llamados “recursivamente enumerables”.
Autómatas de Pila
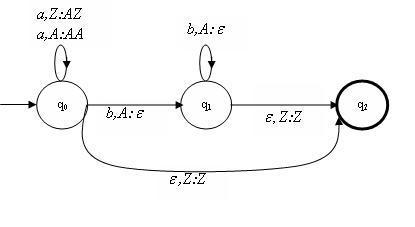
Puesto que los autómatas finitos no son suficientemente poderosos para aceptar los LLC, 1 cabe preguntarnos qué tipo de autómata se necesitar´ıa para aceptar los LLC. Una idea es agregar algo a los AF de manera que se incremente su poder de cálculo. Para ser más concretos, tomemos por ejemplo el lenguaje de los paréntesis bien balanceados, que sabemos que es propiamente LLC. 2 ¿Qué máquina se requiere para distinguir las palabras de paréntesis bien balanceados de las que tienen los paréntesis desbalanceados? Una primera idea podría ser la de una máquina que tuviera un registro aritmético que le permitiera contar los paréntesis; dicho registro sería controlado por el control finito, quien le mandaría símbolos I para incrementar en uno el contador y D para decrementarlo en uno. A su vez, el registro mandaría un símbolo Z para indicar que está en cero, o bien N para indicar que no está en cero. Entonces para analizar una palabra con paréntesis lo que haríamos sería llevar la cuenta de cuántos paréntesis han sido abiertos pero no cerrados; en todo momento dicha cuenta debe ser positiva o cero, y al final del cálculo debe ser exactamente cero. Por ejemplo, para la palabra (())() el registro tomar´ıa sucesivamente los valores 1, 2, 1, 0, 1, 0. Recomendamos al lector tratar de diseñar en detalle la tabla describiendo las transiciones del autómata.
Máquinas de Turing
Así como en secciones anteriores vimos cómo al a˜nadir al autómata finito básico una pila de almacenamiento auxiliar, aumentando con ello su poder de cálculo, cabría ahora preguntarnos qué es lo que habría que a˜nadir a un autómata de pila para que pudiera analizar lenguajes como {a n b n c n}. Partiendo del AP básico (figura 6.1(a)), algunas ideas podrían ser: 1. A˜nadir otra pila; 2. Poner varias cabezas lectoras de la entrada; 3. Permitir la escritura en la cinta, además de la lectura de caracteres. Aunque estas ideas –y otras a´un más fantasiosas– pueden ser interesantes, vamos a enfocar nuestra atención a una propuesta en particular que ha tenido un gran impacto en el desarrollo teórico de la computación: la Máquina de Turing. A. Turing propuso [24] en los a˜nos 30 un modelo de máquina abstracta, como una extensión de los autómatas finitos, que resultó ser de una gran simplicidad y poderío a la vez. La máquina de Turing es particularmente importante porque es la más poderosa de todas las máquinas abstractas conocidas.
La máquina de Turing (abreviado MT, ver figura 6.1(b)) tiene, como los autómatas que hemos visto antes, un control finito, una cabeza lectora y una cinta donde puede haber caracteres, y donde eventualmente viene la palabra de entrada. La cinta es de longitud infinita hacia la derecha, hacia donde se extiende indefinidamente, llenándose los espacios con el carácter blanco (que representaremos con “t”). La cinta no es infinita hacia la izquierda, por lo que hay un cuadro de la cinta que es el extremo izquierdo, como en la figura 6.1(b). En la MT la cabeza lectora es de lectura y escritura, por lo que la cinta puede ser modificada en curso de ejecución. Además, en la MT la cabeza se mueve bidireccionalmente (izquierda y derecha), por lo que puede pasar repetidas veces sobre un mismo segmento de la cinta. La operación de la MT consta de los siguientes pasos: 1. Lee un carácter en la cinta 2. Efectúa una transición de estado 3. Realiza una acción en la cinta Las acciones que puede ejecutar en la cinta la MT pueden ser: Escribe un símbolo en la cinta, o Mueve la cabeza a la izquierda o a la derecha Estas dos acciones son excluyentes, es decir, se hace una o la otra, pero no ambas a la vez.